
Vom Pixel zum Bild
Wie Computer das Sehen lernen und die Forschungsarbeiten von Geistes- und Naturwissenschaftlern unterstützen können
von Björn Ommer
Es heißt, die Augen seien der Spiegel der Seele. Und in der Tat verrät ein Blick in die Augen des anderen viel über dessen innere Gemütslage. Umgekehrt sind die Augen unser Tor zur Außenwelt. Das Sehen ermöglicht es uns, Dinge zu begreifen, die wir nicht greifen können. Das macht es uns beispielsweise möglich, Gefahren aus dem Weg zu gehen, bevor sie uns zu nahe kommen, oder uns an unerreichbar fernen Sternbildern zu orientieren.
Obwohl unsere Augen einen Pupillendurchmesser von weniger als acht Millimetern haben und eine unscheinbar kleine Öffnung zur Außenwelt darstellen, erfassen sie unvorstellbar große Datenmengen. Die pro Sekunde aufgenommene Menge an Rohdaten entspricht mit etwa drei Gigabyte dem Datenvolumen von mehr als einer halben DVD. Die eintreffenden Stimuli sind dabei hochgradig redundant – wirklich relevante Informationen drohen in der Datenflut unterzugehen. Das menschliche Gehirn steht – genau wie eine Maschine, die Ähnliches leisten soll – vor dem Problem, eine komplexe Wirklichkeit aus einem unvollständigen Abbild zu rekonstruieren – einem Abbild auch noch, das es selber generiert hat. Dieses inverse Problem ist die zentrale Herausforderung des Sehens.
Bei dieser Komplexität drängt sich die Frage auf, ob das Sehen und der Prozess des Bildverstehens womöglich unlösbare Probleme sein könnten. Nun, offensichtlich ist dem nicht so. Denn mit dem menschlichen Gehirn existiert ein erstaunlich gut funktionierendes Gegenbeispiel. Doch wie erbringt es diese Leistung? Wir sehen uns hier in einer vergleichbaren Situation wie etwa Isaac Newton beim Verstehen der Gravitation: Aus einem einzelnen Abbild können wir die Wirklichkeit nicht erklären – genauso wenig wie aus einem einzelnen physikalischen Experiment. Wir können aber wie Newton beobachten, dass unsere Welt trotz ihrer hohen Komplexität auch eine große Regularität aufweist: So, wie dieselbe Kraft, die den Apfel zu Boden zieht, den weit entfernten Mond in seiner Bahn hält, weisen selbst sehr verschiedene Objekte verwandte Strukturmerkmale auf. Sie haben etwa eine Tendenz, konvex zu sein, sie zeigen glatte Umrisskanten oder haben eine homogene Textur.

| |
|
Das Ziel der Forschungsarbeiten ist, Computern quasi nach dem Vorbild der Natur das Sehen beizubringen. Die Maschinen sollen lernen, Objekte ähnlich wie das menschliche Gehirn zu erkennen und zu interpretieren.
|
Diese Regelmäßigkeit der Welt ermöglicht es uns, das oben beschriebene Problem zu lösen: Während wir aus einem einzigen Bild nur unzureichend auf die Wirklichkeit rückschließen können, können wir mithilfe vieler früher betrachteter Bilder das Sehen lernen, da die Bilder stets dieselben Regelmäßigkeiten aufweisen.
Doch das Ziel ist nicht nur, Regelmäßigkeiten oder Charakteristiken zu erkennen, die Objekte auszeichnen. Es gilt auch zu verstehen, wie eine große Flut heterogener Stimuli, die über unsere Netzhaut auf das Gehirn einströmen, miteinander zu komplexen Objekten verbunden werden. Mit den Worten des Gestaltpsychologen Max Wertheimer gesprochen stehen wir am Fenster, und unsere Augen beobachten lediglich lokale Helligkeitsunterschiede oder Farben – dennoch erkennen wir letztlich Objekte wie Bäume oder Menschen. Das Gruppieren von Perzepten erlaubt es uns, viele wenig informative Entitäten zu einem größeren Ganzen zu aggregieren. Dieser Vorgang ist für das Erkennen von Objekten unerlässlich.
Das Ziel unserer Forschungsarbeiten ist es, Computern gleichsam nach dem Vorbild der Natur das Sehen beizubringen: Die Maschinen sollen lernen, Objekte ähnlich wie unser Gehirn zu erkennen und Bilder zu interpretieren. Um dies zu erreichen, haben wir Algorithmen entwickelt, mit denen der Computer anhand eines kleinen Satzes von Trainingsbildern lernen kann, die vielen Bildpunkte eines Bildes zu bedeutungstragenden Kompositionen zu gruppieren. Darüber hinaus lernt der Computer, Charakteristiken zu erkennen, die eine Kategorie von Objekten von einer anderen Objektkategorie unterscheidet. Das Gruppieren und Erkennen von Objekten ist dabei derart miteinander verzahnt, dass die bedeutungstragenden Objektbestandteile aus dem störenden Hintergrund gelöst und gruppiert werden können. Erst dadurch werden sie als Objekte erkennbar.

| |
|
|
Diese Regelmäßigkeit der Welt ermöglicht es uns, das oben beschriebene Problem zu lösen: Während wir aus einem einzigen Bild nur unzureichend auf die Wirklichkeit rückschließen können, können wir mithilfe vieler früher betrachteter Bilder das Sehen lernen, da die Bilder stets dieselben Regelmäßigkeiten aufweisen.
Doch das Ziel ist nicht nur, Regelmäßigkeiten oder Charakteristiken zu erkennen, die Objekte auszeichnen. Es gilt auch zu verstehen, wie eine große Flut heterogener Stimuli, die über unsere Netzhaut auf das Gehirn einströmen, miteinander zu komplexen Objekten verbunden werden. Mit den Worten des Gestaltpsychologen Max Wertheimer gesprochen stehen wir am Fenster, und unsere Augen beobachten lediglich lokale Helligkeitsunterschiede oder Farben – dennoch erkennen wir letztlich Objekte wie Bäume oder Menschen. Das Gruppieren von Perzepten erlaubt es uns, viele wenig informative Entitäten zu einem größeren Ganzen zu aggregieren. Dieser Vorgang ist für das Erkennen von Objekten unerlässlich.
Das Ziel unserer Forschungsarbeiten ist es, Computern gleichsam nach dem Vorbild der Natur das Sehen beizubringen: Die Maschinen sollen lernen, Objekte ähnlich wie unser Gehirn zu erkennen und Bilder zu interpretieren. Um dies zu erreichen, haben wir Algorithmen entwickelt, mit denen der Computer anhand eines kleinen Satzes von Trainingsbildern lernen kann, die vielen Bildpunkte eines Bildes zu bedeutungstragenden Kompositionen zu gruppieren. Darüber hinaus lernt der Computer, Charakteristiken zu erkennen, die eine Kategorie von Objekten von einer anderen Objektkategorie unterscheidet. Das Gruppieren und Erkennen von Objekten ist dabei derart miteinander verzahnt, dass die bedeutungstragenden Objektbestandteile aus dem störenden Hintergrund gelöst und gruppiert werden können. Erst dadurch werden sie als Objekte erkennbar.
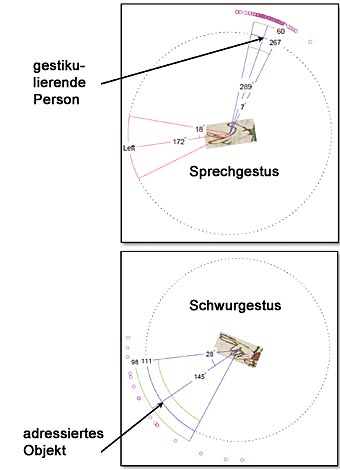
| |
|
Um Maschinen ähnlich wie Menschen Bilder sehen und interpretieren zu lassen, haben die Forscher Algorithmen entwickelt, die es den Computern ermöglichen, Charakteristika zu erkennen, die eine Kategorie von Objekten – etwa die Gestik während des Sprechens (Bild oben) – von anderen Objektkategorien unterscheiden, etwa Gesten, die ein Gelöbnis anzeigen (Bild unten). Das Gruppieren und Erkennen von Objekten ist eng miteinander verzahnt: Bedeutungstragende Objektbestandteile müssen aus dem störenden Hintergrund gelöst und zu Kategorien, etwa Zeige-Gesten, zusammengefasst werden.
|
Ein solches Unternehmen ist bei allen theoretischen Überlegungen ein in großem Umfang praktisches Unterfangen: Erst im Experiment mit konkreten Bildern und den mit der jeweiligen Anwendung verbundenen Herausforderungen zeigt sich das Potenzial eines solchen Objekterkennungssystems.
Die vielfältigen Möglichkeiten zur interdisziplinären Kooperation, die in der Universität Heidelberg bestehen, sind für unsere Forschungsarbeiten essenziell. Gemeinsam mit Lieselotte Saurma, Professorin der mittelalterlichen Kunstgeschichte, untersuchen wir beispielsweise, inwieweit sich computergestützte Verfahren einsetzen lassen, um mittelalterliche Rechtsgesten zu analysieren.
Wir haben beispielsweise anhand der verschiedenen Bilderhandschriften des Sachsenspiegels die automatische Repräsentation und Erkennung von Rechtsgesten erforscht, um damit eine Grundlage für die Entwicklung einer quellenadäquaten Analyse zu legen: In der rechtshistorischen Forschung existiert bislang kein allgemein anerkanntes textbasiertes Klassifikationssystem, nach dem sich Gesten standardisiert benennen ließen. Begriffliche Annotationen, mit denen man in einer Bilddatenbank suchen könnte, erfassen daher nicht die Gesten selbst, sondern benennen nur den übergeordneten Handlungszusammenhang, in dem sie in Erscheinung treten. Die gezielte Suche nach den spezifischen Merkmalen einer Handgebärde oder einer Körperhaltung ist daher unmöglich.
Eine Suchfunktion, die es erlaubt, Bilder nicht über den Umweg einer textuellen Verschlagwortung wie etwa bei der Google-Bildersuche zu erschließen, sondern direkt auf der Ebene des Bildinhaltes zu durchsuchen, ist hier ein zentrales Desiderat der Forschung. Dies eröffnet zudem die Möglichkeit, Bildzeugnisse unterschiedlicher Rechtskulturen oder anderer Bereiche ritualisierten Handelns vergleichend zu untersuchen und die zentrale Frage nach den transkulturellen Übertragungsprozessen kodifizierter Gesten zu beantworten.
Geisteswissenschaftler unterschiedlichster Disziplinen haben heute essenziellen Bedarf für derartige Suchsysteme: Aufgrund großer Digitalisierungsprojekte, wie sie beispielsweise von der Heidelberger Universitätsbibliothek betrieben werden, hat die Menge an verfügbaren Daten in den letzten Jahren derart zugenommen, dass für die Forschung höchst relevante Exemplare in der Datenflut unterzugehen drohen.
Wir haben deshalb aufbauend auf unserem Objektdetektions-Algorithmus alle Objekte einer Kategorie entsprechend ihrer Ähnlichkeit automatisch geordnet. Auch wenn Bilder über viele verschiedene Bücher verstreut sind, können sie auf diese Weise in einer einzigen Grafik zueinander in Beziehung gesetzt werden. Dies erlaubt dem anwendenden Wissenschaftler einen völlig neuen Zugang zu seinem Bildkorpus: Der menschliche Betrachter könnte nur Seite für Seite betrachten und Objekt für Objekt untersuchen – der Computer aber ist imstande, dem Forscher das große Ganze in einer einzigen Übersicht zu präsentieren.
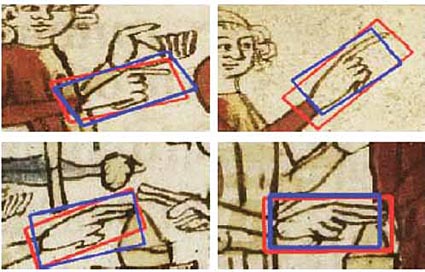
| |
|
|
Und noch ein weiterer Vorteil kommt hinzu: Während ein Mensch wie beim Memory-Spiel nach einiger Zeit die früheren Exemplare vergessen hat, kann der Computer die Informationen alle gleichzeitig in eine wohldefinierte Ordnung bringen. Der entwickelte Algorithmus schlüsselt dabei die Variabilität von Objektkategorien auf und ermöglicht es beispielsweise, die gesamte Variabilität der mittelalterlichen Kronen aus den Codices Palatini germanici mit einem Blick zu betrachten. Basierend auf der automatischen Analyse der Variabilität einer Objektkategorie wie die der Kronen konnten wir unseren Ansatz auch verwenden, um Objekte je nach Zeichnungsstil der Werkstatt zuzuordnen, der sie entstammen.
Unser Ansatz, Computern das Sehen beizubringen, findet nicht nur in den Geistes-, sondern auch in den Naturwissenschaften Anwendung, beispielsweise in einer Kooperation mit den Heidelberger Wissenschaftlern Rohini Kuner (Pharmakologie) und Thomas Kuner (Neuroanatomie). Gemeinsam mit Biologen und Me-dizinern versuchen wir zu verstehen, wie sich Nerven-gewebe bei chronischen Schmerzen verändert. Dazu werden anhand einer Sequenz dreidimensionaler Multiphotonenmikroskopie-Bilder die Degeneration von Nervenfasern unter dem Einfluss von Schmerzen und der sich anschließende Heilungsprozess untersucht. Wie der Computer die Variabilität mittelalterlicher Kronen aufschlüsseln kann, kann er nun auch die zeitlichen Veränderungen von Nervenfasern analysieren – die grundlegenden algorithmischen Prinzipien sind gleich.
Die genannten Anwendungen zeigen exemplarisch die Bedeutung von Algorithmen auf, mit denen Computer zur Semantik von Bildern vordringen können: An „sehenden Maschinen“ besteht ein großer interdisziplinärer Bedarf.

| |
|
Foto: Friederike Hentschel
|
Prof. Dr. Björn Ommer leitet seit dem Jahr 2009 in der Universität Heidelberg die Arbeitsgruppe „Computer Vision“, die am Interdisziplinären Zentrum für Wissenschaftliches Rechnen (IWR) und im Zukunftskonzept Transkulturelle Studien angesiedelt ist. Zuvor forschte er an der University of California, Berkeley, auf dem Gebiet der visuellen Objekterkennung.
Kontakt: ommer@uni-heidelberg.de